
El estudio presenteó la aplicación de deep learning para el pronóstico de producción de yacimientos no convencionales.
Los pronósticos de producción de aceite y gas son una de las tareas más importantes en la administración integral de yacimientos. Estos pronósticos son de vital importancia para estimar las reservas remanentes, optimizar la producción y planificación de proyectos, entre otros.
Actualmente se utilizan modelos empíricos (curvas de declinación), semi- analíticos (Balance de materia) y analíticos (simulación numérica de yacimientos) para los pronósticos de producción; si bien, las curvas de declinación son usadas frecuentemente por su fácil aplicación, la incertidumbre asociada es bien conocida; impactando directamente en la estrategia de planeación de explotación y producción de hidrocarburos.
Por otro lado, la simulación de yacimientos requiere una gran cantidad de información, tiempo y costo. En este artículo, se usan algoritmos de Deep learning para el pronóstico de producción en yacimientos no convencionales; siendo ésta es una herramienta impulsada por datos y de aprendizaje automático.
El término machine learning fue definido por Arthur Samuel, quien lo define: “campo de estudios que da la habilidad a las computadoras de aprender sin ser programadas explícitamente”.
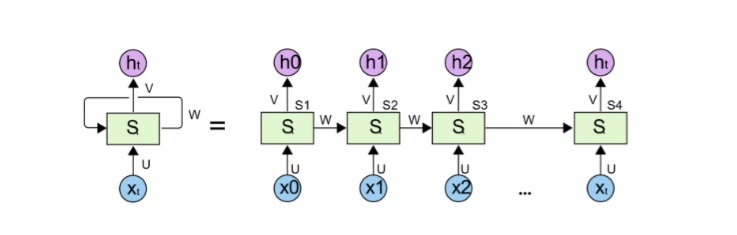
Asimismo, el término Deep learning es una subrama del machine learning; el cual simula el comportamiento del cerebro humano, dando la habilidad de aprender de grandes cantidades de datos.
Te puede interesar: Corrección de presión de saturación por efectos de extracción
Durante el estudio, la red neuronal LSTM presentó mejores ajustes y un menor error cuadrático medio que los modelos convencionales de declinación; mostrando un comportamiento más representativo de los datos reales de producción de gas en yacimientos no convencionales.
Adicionalmente, la red neuronal mostró un mejor ajuste en casos donde existen mucha dispersión de los datos de producción. Demostrando un mejor ajuste en periodos con mucha incertidumbre.
Igualmente, el modelo puede mejorarse implementando más parámetros de entrenamiento como son el uso de datos de presión de fondo fluyendo; gasto de agua y variaciones en estrangulador, para mejorar el ajuste de la red neuronal.
Asimismo, el entrenamiento con mayor un mayor número de pozos representativos generará mejores rendimientos de ajuste y menos márgenes de error.
Los ingenieros Abimael Avila Torres, Oliver Hernández Ambrosio, Jorge Arévalo Villagrán y Francisco Castellanos Páez presentaron el trabajo en la reciente edición del Congreso Mexicano del Petróleo (CMP).