
La optimización del proceso de evaluación de nuevas localizaciones en campos maduros a través de la aplicación de técnicas de Machine Learning en el análisis de datos históricos del subsuelo y de producción.
Durante el estudio se aplicó el algoritmo Kmeans. Es un algoritmo de clasificación no supervisado que agrupa objetos en k números de clúster, dependiendo de la métrica utilizada.
Una vez escogido el número de grupos, k, se establecen k centroides aleatoriamente en el espacio de los datos. Cada elemento del conjunto de los datos se asigna al centroide más cercano. Se actualiza la posición del centroide de cada grupo tomando como nuevo centroide la posición del promedio de los objetos pertenecientes a dicho grupo.
Asimismo, se empleó un análisis de conglomerados híbrido. Contempla procedimientos en los cuales se utilizan más de un análisis de conglomerados; ya sea con el fin de simplificar la dimensión de los datos u obtener un análisis mas preciso. Primero se usó un análisis de kmeans para obtener un conjunto de pequeños grupos que por la métrica utilizada tienen características muy parecidas(cercanas) y después un análisis aglomerativo con métrica de Pearson.
Durante el trabajo se contó con información de hasta 170 pozos. Datos relacionados a la localización geográfica, formaciones geológicas e intervalos disparados, y datos geofísicos (también datos de producción, pero eso amerita un análisis aparte); lo cual hizo que se tuvieran alrededor de 2 millones de registros con alrededor de 20 variables que los describían.
Te puede interesar: Modelo numérico para diagnosticar la irrupción de agua YNF
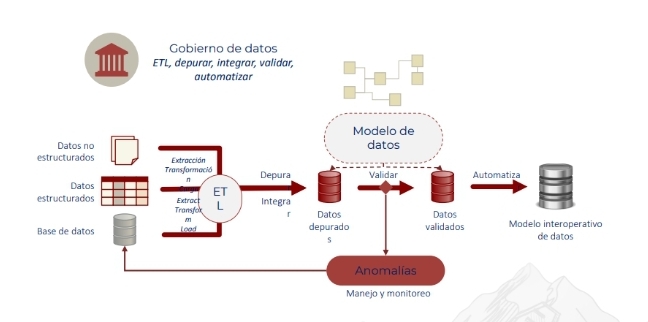
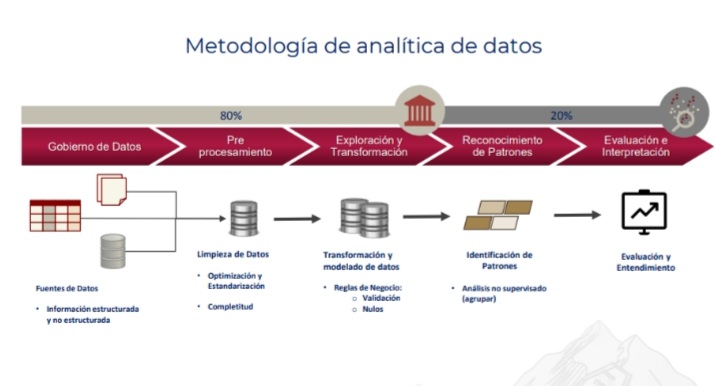
Para el desarrollo de la metodología es importante establecer un equipo multidisciplinario de especialistas del negocio; así como validar la calidad del dato de insumo, el 80% del esfuerzo del trabajo radica en aplicar gobierno y establecer un modelo de datos.
Asimismo, fortalecer la capacitación y habilidades de especialistas del negocio para aplicar tecnologías de analítica de datos; que les permita administrar la información y favorecer a los grupos multidisciplinarios en la toma de decisiones.
Finalmente, Pemex, a través de sus especialistas de negocio, debe de establecer un gobierno del dato para homologar flujos de trabajo. Asimismo, facilitar el análisis de campos mediante la aplicación de metodologías con analítica de datos; con el fin de alcanzar procedimientos automatizados de integración de información que permitan obtener la jerarquización de pozos con oportunidades en campos maduros.
Los ingenieros Jorge Pedro Cruz Andrade, Carmelo Hernández Martínez, Edgar Adrian Priego Domínguez y Jorge Luis Hernández Castillejos presentaron el trabajo en la reciente edición del Congreso Mexicano del Petróleo.